
I am currently a Ph.D. candidate in Tianjin Key Laboratory of Visual Computing and Intelligent Perception (VCIP) and Media Computing Lab (MCLab) at the College of Computer Science, Nankai University, supervised by Prof. Ming-Ming Cheng and Prof. Qibin Hou. Prior to this, I completed seven years of undergraduate and master's studies at Dalian University of Technology (DUT).
My current research interest includes temporal modeling, open-vocabulary understanding and multi-modal learning.
I am dedicated to contributing to open-source projects, and my work can be found in HVision-NKU. Additionally, I maintain a list of Awesome Open-Vocabulary Semantic Segmentation resources.
If you're interested in my research or have any research-related questions, please feel free to contact me via email at yunhengli [at] mail.nankai.edu.cn or yunheng.li.21 [at] gmail.com.
📚 Publications
* Eauql contribution. # Corresponding author
Preprint
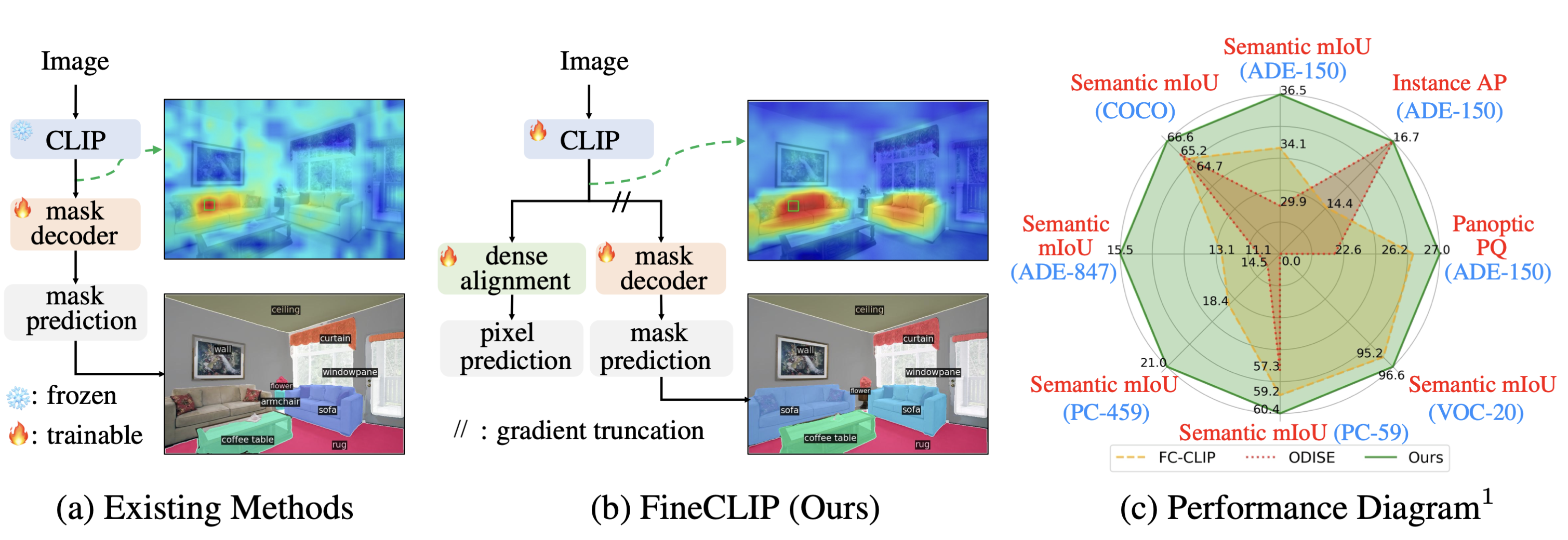
Align Before Segment: Understanding Visual Encoder Fine-tuning for Open Vocabulary Segmentation
Yunheng Li, Quansheng Zeng, Zhong-Yu Li, Enguang Wang, Qibin Hou#, Ming-Ming Cheng
FineCLIP is an align-before-segment framework that fine-tunes CLIP with dense image-text alignment, notably enhancing open-vocabulary segmentation performance.
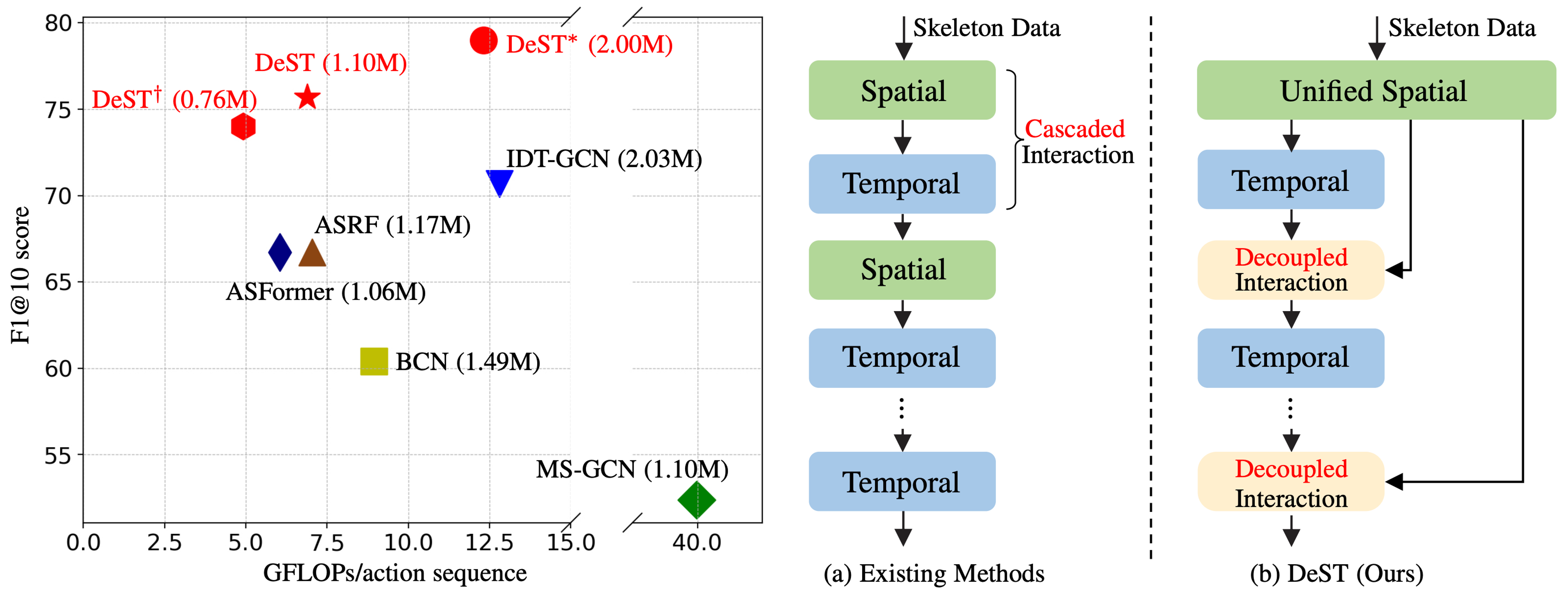
A Decoupled Spatio-Temporal Framework for Skeleton-based Action Segmentation
Yunheng Li, Zhong-Yu Li, Shanghua Gao, Qilong Wang, Qibin Hou#, Ming-Ming Cheng
Decoupled Spatio-Temporal (DeST) framework is the first to decouple spatio-temporal modeling for effective skeleton-based action segmentation.
Conference
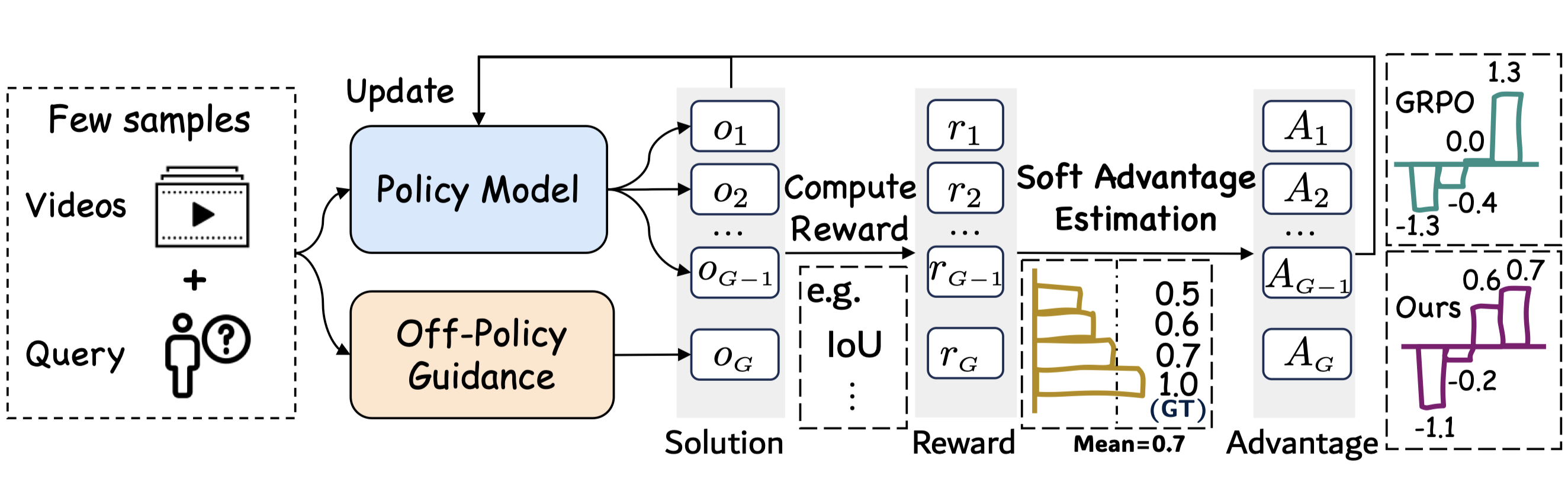
TempSamp-R1: Effective Temporal Sampling with Reinforcement Fine-Tuning for Video LLMs
Yunheng Li, JingCheng, Shaoyong Jia, Hangyi Kuang, Shaohui Jiao, Qibin Hou#, Ming-Ming Cheng [Paper] [Code] [Huggingface]
TempSamp-R1 leverages ground-truth annotations as off-policy supervision to provide temporally precise guidance, effectively compensating for the sparsity and misalignment in on-policy solutions in Video LLMs.
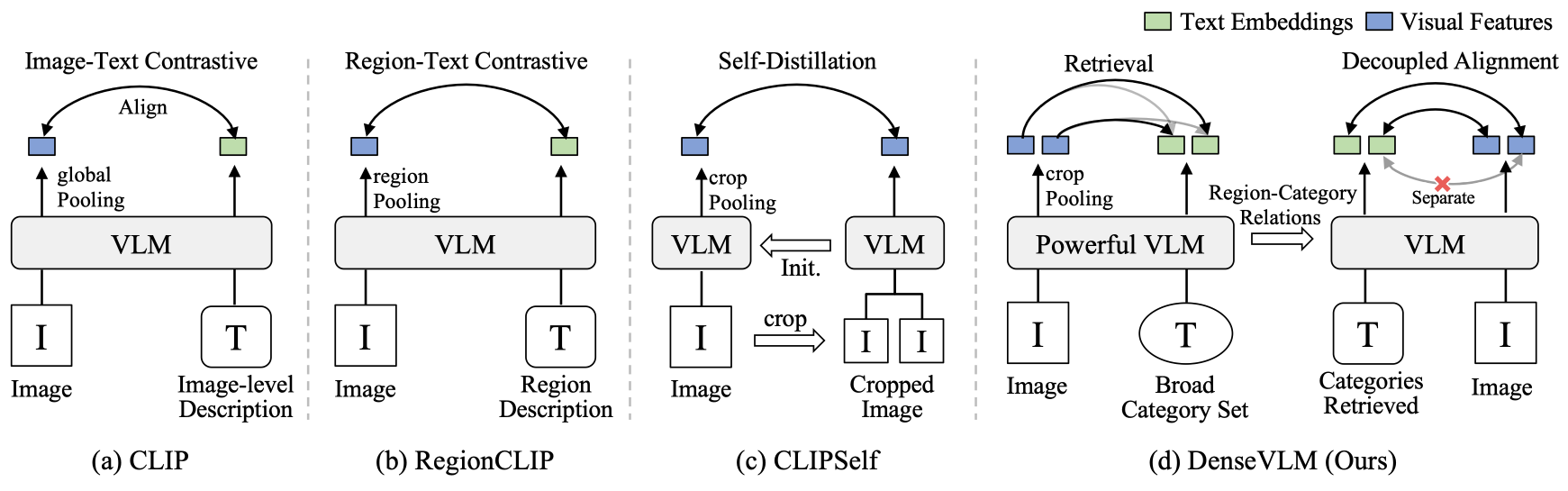
Unbiased Region-Language Alignment for Open-Vocabulary Dense Prediction
Yunheng Li, Yuxuan Li, Quansheng Zeng, Wenhai Wang, Qibin Hou#, Ming-Ming Cheng
[Paper] [Code] [Huggingface] [中译版]
DenseVLM is an unsupervised fine-tuning framework, which retrieves region-level semantics from a powerful vision-language model and decouples foreground and background features to achieve unbiased region-language alignment.
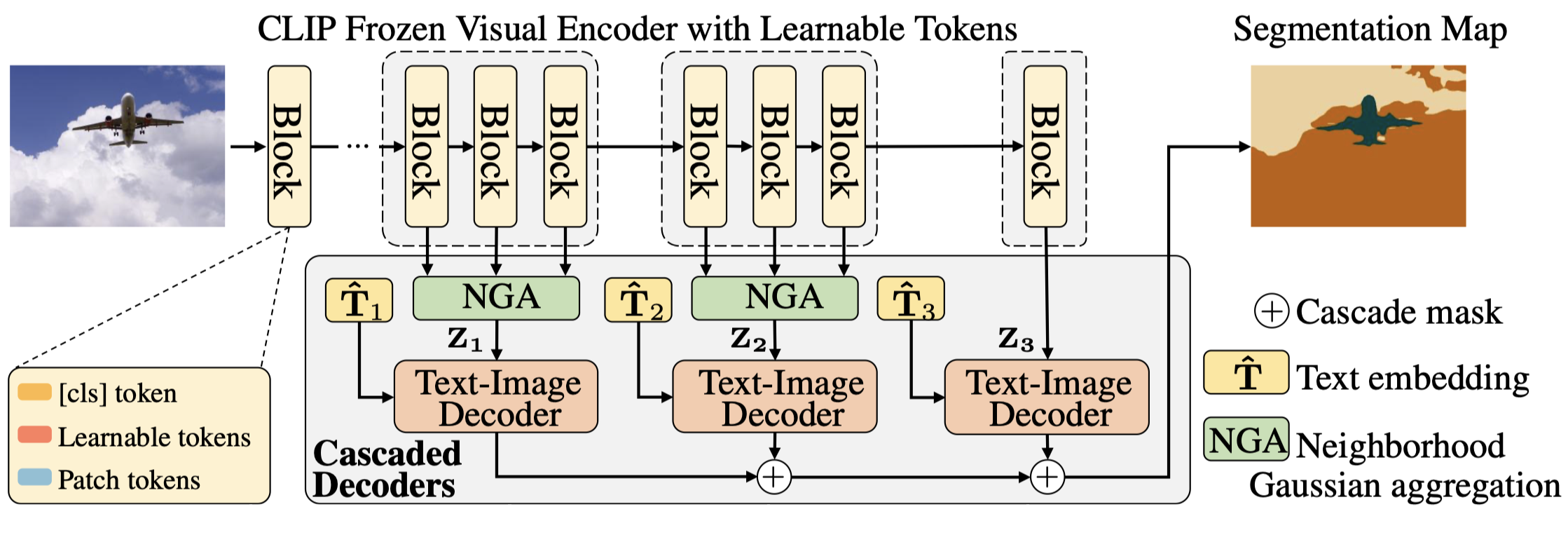
Cascade-CLIP: Cascaded Vision-Language Embeddings Alignment for Zero-Shot Semantic Segmentation
Yunheng Li, Zhong-Yu Li, Quansheng Zeng, Qibin Hou#, Ming-Ming Cheng
[Paper] [Code] [中译版] [集智书童] [Poster]
Cascade-CLIP aligns vision-language embeddings via cascaded manner, effectively leveraging CLIP’s multi-level visual features for better zero-shot segmentation.
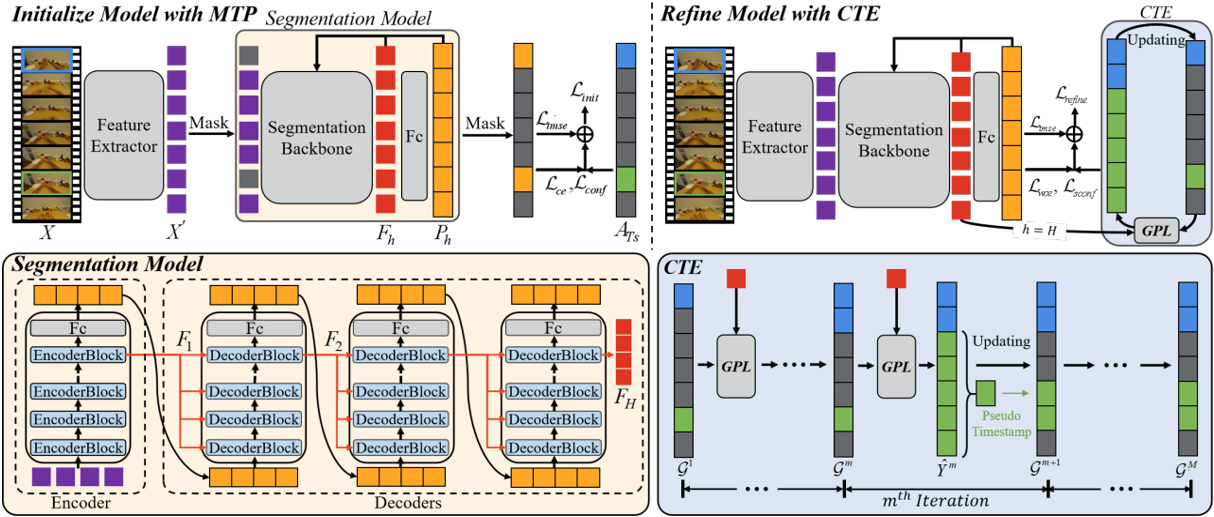
Reducing the Label Bias for Timestamp Supervised Temporal Action Segmentation
Kaiyuan Liu*, Yunheng Li*, Shenglan Liu#, Chenwei Tan, Zihang Shao
D-TSTAS employs a masked timestamp prediction method to reduce dependency on timestamps and a center-oriented timestamp expansion technique to capture semantic-rich motion representations.
Journal
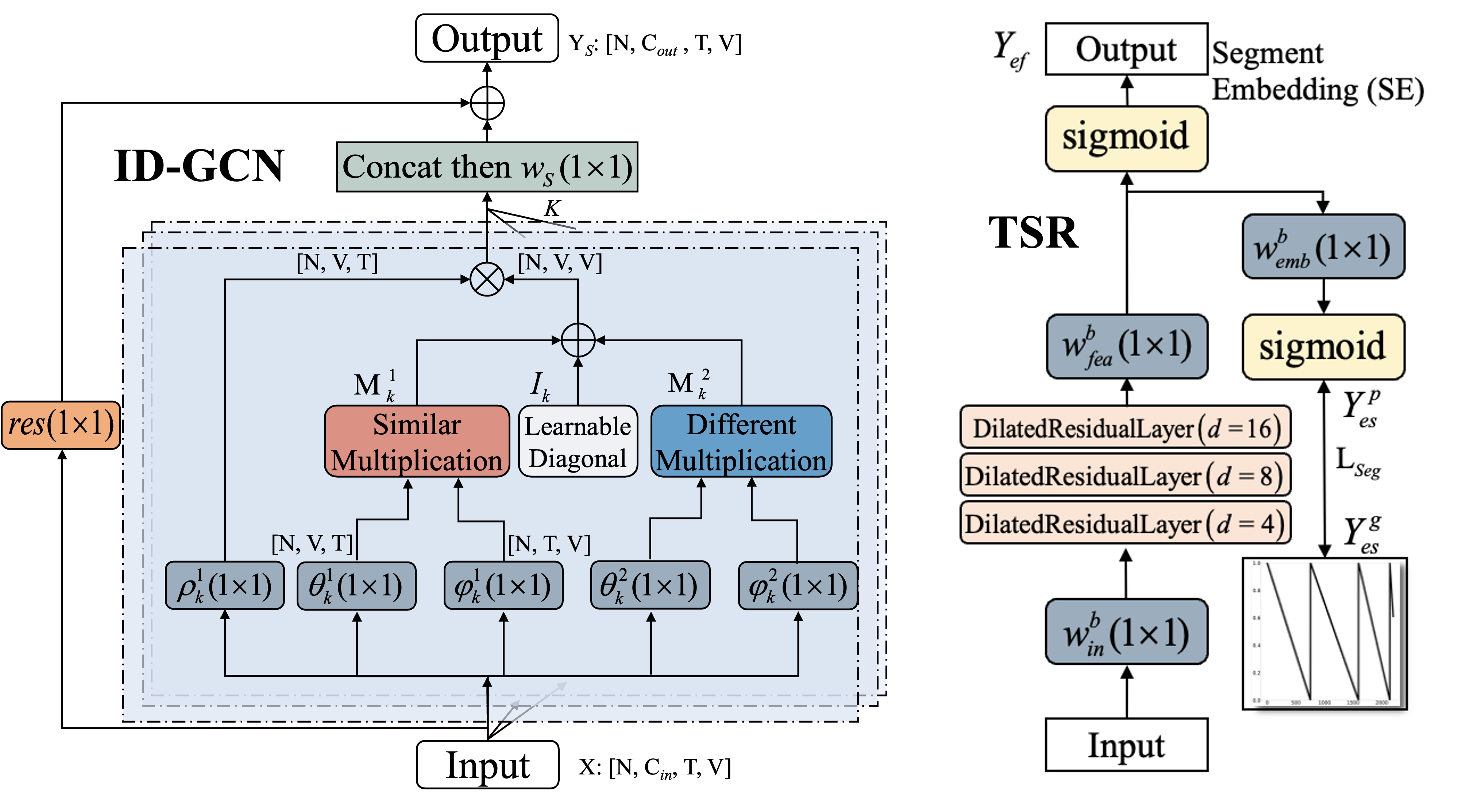
Yunheng Li, Kai-Yuan Liu, Sheng-Lan Liu#, Lin Feng, Hong Qiao
IDT-GCN employs an Involving Distinction Graph Convolutional Network (ID-GC) to effectively capture both similar and differential dependencies among spatial joints through multiple adaptive topologies. Additionally, Temporal Segment Regression (TSR) is used to model action sequences.
📃 Others
Revisiting Efficient Semantic Segmentation: Learning Offsets for Better Spatial and Class Feature Alignment. IEEE ICCV, 2025.
Shicheng Zhang, Yunheng Li, et al. [Paper] [Code]
Spatial Focus Attention for Fine-grained Skeleton-based Action Tasks. IEEE SPL, 2022. Kaiyuan Liu, Yunheng Li, et al. [Paper]
Double Attention Network Based on Sparse Sampling. IEEE ICME, 2022. Zhuben Dong, Yunheng Li, et al. [Paper]
Eicient Two-Step Networks for Temporal Action Segmentation. Neurocomputing, 2021. Yunheng Li, Zhuben Dong, Kaiyuan Liu, et al. [Paper] [Code]
Temporal Segmentation of Fine-gained Semantic Action: A Motion-centered Figure Skating Dataset. AAAI, 2021. Shenglan Liu, Aibin Zhang*, Yunheng Li*, et al. [Paper] [Datasets]
🛠️ Orobot: Ball-Wheel Self-Balancing Robot
🎓 Educations
- 2023.09 - Present, Ph.D. Student in Computer Science and Technology, Nankai University, Tianjin, China.
- 2020.09 - 2023.06, M.S. in Computer Science and Technology, Dalian University of Technology, Dalian, China.
- 2016.09 - 2020.06, B.S. in Electrical Engineering and Automation, Dalian University of Technology, Dalian, China.
👥 Services
- Conference: CVPR; ICCV; NeurIPS; ECCV; etc.
- Journal: IEEE TCSVT; Neurocomputing.